supermemo 学习记录
SuperMemo词库加工
图片修改工具:inpaint
可以非常快速涂抹图片中的部分内容,并且保证在修改后保持与周边图像的协调,非常方便快捷!
单词画廊
- 下载单词画廊破解版,并安装到iphone
- copy dict.db文件,该文件为单词画廊图片、声音文件的存放地,格式为sqlite 3
- 运行:?: python脚本可直接将图片文件导出,每张图片单独存为文件
- 其图片由于叠加了单词文本和解释,根据音图建立MIF原理,需要将图片上的位置去除掉
- 使用inpaint软件可以对其进行修改,inpaint较弱智,不方便批量操作,可使用autoit脚本来加速操作进程
extreme english
- 下载EE学习包,其格式为supermemo UX格式
- 运行:?: python脚本可对其进行解包,解包后的文件包括单词列表xml文件、mp3语音和png图片,需要对其进行对应关联
- png文件在supermemo15中并不能支持,需要将其转换为jpg格式
语音库
- 朗文8万语音库音质不错,原始文件格式为wav
- 可使用lame转换为mp3格式,采用批处理命令处理,为加快处理速度,可将批处理文件分成多个同时运行
supermemo15 Q&A文件
- 经过测试,舍得的转换精灵不太好用,还是直接编辑Q&A文本比较直接
- 不支持png图像文件格式,:!:浪费了很多时间
- 文件编码为UTF-8,回车换行为windows方式
supermemo 优化
快捷键修改
具有以下功能:
1、用z、x、c、v、b、n做快捷键,打分后直接进入下一问题,不用按【next repeatition】按钮
2、在final drill 模式下,使用SHIFT+N可以循环浏览需要复习的材料,再按一次SHIFT+N停止循环
使用方法:
1、需要安装autoit程序
2、将该脚本放到sm.exe执行文件所在目录
3、启动时直接运行脚本,会自动启动supermemo
4、退出时直接关闭supermemo,脚本会自动退出
不足:
1、由于使用了全局快捷键,在不退出的情况下使用其他程序时,输入相关快捷键时会有干扰,比如按【z】时,输入的是【5】
supermemmo 绿色版本
supermemo 15由于进度问题,在不同机器上使用时会存在进度同步问题,解决办法之一是将其搬到U盘上,随身携带,即插即用,具体步骤如下:
1. 在U盘上建立根目录,如SLEMedia
1. 将supermemo程序目录copy到SLEMedia下
1. Q&A文件对mp3文件的引用路径修改为相对路径,形如file:///../../supermemo/sysytem/1/1/1.htm
**存在的问题是U盘读写操作较慢,在连续播放时有停顿感,需要优化**
SuperMemo的复习进程
近日在舍得英语魔法学苑或VeryCD上提到“复习量”问题的朋友比较多,看来对SuperMemo确实比较迷茫,有感于此,舍得便来讲解一下SuperMemo中的复习安排。
SuperMemo其实有两个复习进程,用舍得的话讲就是,一个是当天的,另一个是“非当天”的。
当天的复习进程主要是为了帮助你那些你还吃不准意思的记忆材料,评分在3以下的记忆材料均会进入当天的复习进程。大家可以通过统计窗口的Outstanding一栏中观察一下,这一栏数据的格式是:XX+0+XX el.(X为数字),其中前一个XX是“非当天”的复习进程,后一个XX就是当天的复习进程。

SuperMemo并没有死板地套用艾宾浩斯的原理,因为从记忆曲线中讲,一般记住后,“在5分钟后重复一遍,20分钟后再重复一遍,1小时后,12小时后,1天后,2天后,5天后,8天后,14天后就会记得很牢。”但是,对于那些你本来就记得挺牢的记忆材料,你还需要这样子去重复吗?
其实,在艾宾浩斯后来的记忆的实验中也发现了这个问题,他发现,记住12个无意义音节,平均需要重复16.5次;为了记住36个无意义章节,需重复54次;而记忆六首诗中的480个音节,平均只需要重复8次!这个实验说明了,凡是理解了的知识,就能记得迅速、全面而牢固。不然,愣是死记硬背,那也是费力不讨好的。
另外,在记忆曲线中,当天的这个“5分钟、20分钟、1小时和12小时”的间隔也并非是绝对的。因此,在SuperMemo的中,对此进行了简化,把当天何时复习的主动权就交回给学习者手上,这可以让我们有更多的精力来对待那些难以搞定的记忆材料,确实是一大创举。
再来讲讲“非当天”的复习进程,这才是记忆的重头戏,因为这个复习进程安排的好坏,直接决定了记忆的效率和效果。SuperMemo会根据你的评分——即你对记忆材料的掌握程度来给它们安排合理的复习时间。大家可以通过SuperMemo的工作量窗口来观察它的复习安排(你可以按下快捷键Ctrl+W来调出此窗口),下图是舍得学习的某个词库:
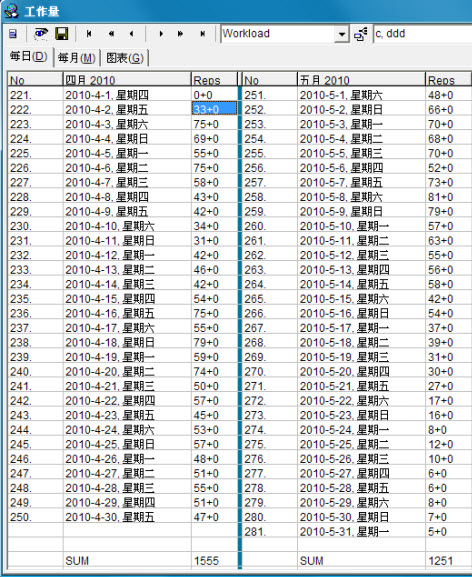
从上图可以看到,虽然今天才4月2日,但是复习的进程却将4、5月份都排满了(事实上SuperMemo给舍得排的计划一直到2011年2月27日)。这个图其实很简单,大家只要看每月的第三栏(即Reps)中即可,前一个数字就是你要复习的数量,后一个数字是你要复习的主题数量(SuperMemo里材料分为Element和Topic,不过后者用得较少)。双击相应的栏位可以进入SuperMemo的浏览器(相当于资源管理器),即可看到这一天你所要复习的具体的单词。不仅如此,如果你想要知道某个单词的复习历史的话,你可以在学习窗口按下快捷键Ctrl+Shift+H来调出该单词的复习数据,如下图:
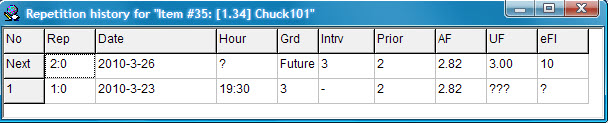
这样的详尽的数据在同类软件中是不多见的,好多软件厂家惟恐自己的算法被人掌握,竭尽所能地隐藏与算法相关的信息,但是对SuperMemo来说,这类对其他厂家来说是“秘密”的内容却大大方方地呈现在用户面前,这不得不让人佩服软件设计者的实力。因为如果不是对自己的算法有足够的自信,是绝不会公开这些数据的,否则的话,岂不是给自己的竞争对手提供攻击自己的数据吗?
在这篇文章中,舍得向大家介绍了SuperMemo的两个复习进程,当天的复习进程大家可以通过统计窗口的Outstanding一栏来观察,这一复习进程的学习程序把它叫做“Final Drill”。“非当天”的复习进程大家可以通过工作量窗口来进行观察和分析,大家在学习的时候不妨关注一下这两个数据,你可以根据这个数据来合理地安排自己学习新材料的数量,在保证学习效果的同时,充分提高学习的效率。
SuperMemo是怎样工作的?
背单词一直是我们中国人学习英语中最头疼的问题之一,通常学习者会花大把的时间在“背单词”上,而往往收效甚微。
SuperMemo的出现无疑是英语学习者的福音。这是一个拥有20多年历史的软件,开发者是波兰人Piotr Wozniak。跟其它同类软件略有不同的是,supermemo原来是作为一个博士论文的研究而开发的,后来才进入商业软件的领域。
SuperMemo只专注于一件事:如何帮助你合理地安排每个单词的背诵间隔,这个记忆间隔安排得越科学,使用者的背诵效率就越高。使用SuperMemo,能够帮助你在“背单词”这个环节上节省大量的时间。
那它是怎么做到的呢?
在美国1999年世界记忆学大会上公布了一个成果,是“关于艾宾浩斯记忆曲线的定量性研究”研究成果表明在人类大脑记忆过程中,在某一时间内,会形成三种记忆,即感觉记忆、短时记忆和联想记忆。
我们以一个记单词事件为例,当你开始记一个单词时,你在几秒中之内会产生一个“感觉记忆”,这个感觉记忆转瞬即失,每个人各不相同,但基本上都在3、4秒之内,这个在记单词时不会感觉太深,在什么时候感觉深呢?感觉记忆之后还会有一个“短时记忆”,也叫“工作记忆”。这个记忆的延续时间也各不相同,大概在4~16个小时之间,不同的人相差四倍,这个在什么时候用到呢?比如:老师在课间给学生说:下节课要听写昨天学的单词,你特别着急,下课后赶紧背,管不管用,管用!但是放学回家吃顿饭或玩了以下,就什么也记不起来了,这是短时记忆,也是记完后马上会消失掉。在这两个记忆消失的过程中,会产生一个长时记忆痕迹,这是我们最关心的东西,也是最有用的东西,你真正的记忆,学习一个单词,学习任何东西,都会用到长时记忆痕迹,它是一个抛物线,就会有个最顶点,是个最高点,这是你这次记忆单词的记忆最强点,这个点能产生一个记忆强度,在这,还能产生一个记忆时间T,在某个时间段,你对这次记忆单词会产生一个这次的一个最强点,那么,我们简单的来说,如果有谁能找到这点,这个时间段T,在这进行第二次的拉高复习,这是最有效的,我们翻书,我们看小纸片,其实是在模拟这个T,这个重复时间,即记忆黄金序列是由每个遗忘点排列而成。
这个时候,问题就来了,你怎么知道哪个时间才是黄金时间?这个记忆黄金序列如何安排才合理?其实这个时间你可以根据遗忘曲线的原理来“手工”计算的(SuperMemo官方网站曾经有这样的一篇指导性文章),不过这样一来,用来计算的时间比真正用来学习的时间还要多!但是有了SuperMemo就不一样了,它自动就会给你安排好下次复习的时间,这就是SuperMemo存在的最大价值所在。
在SuperMemo的算法中,会根据单词的掌握程度不同,安排不同的复习间隔。实践证明,这种设计相当有效。
SuperMemo按单词的掌握程度分为六个等级,(这六个等级的描述舍得在《为什么选SuperMemo?》一文中介绍得很详细,在此不再赘述。舍得会在下一篇文章《奇迹智能记忆和SuperMemo的评分等级的对比》会对此作进一步分析;)单词越熟悉,相应所需的复习次数也就越少。这样才能真正把“好钢用在刀刃上”。所以在使用SuperMemo的时候,你能够用最少的复习次数获得最佳的记忆效果。
所以说,SuperMemo是一个非常强劲的辅助记忆工具,每个人都可以利用它来提高自己的记忆效率。现在SuperMemo最新的版本是2008,这个版本舍得已经汉化了,大家可以点击下边的链接下载:点击转到下载页面。你还在等什么?赶紧行动吧!越早使用,越早受益。
浅析SuperMemo的评分体系
为何使用评分体系?
现在市场上用来背单词的软件非常多,但优秀的寥寥无几。我们选择背单词软件的目的,就是为了帮助自己节省用来背诵的时间,提高背诵的效率,快速增加英语词汇的原始积累。一款背单词软件是否优秀,首先就要看它的算法是否优秀,换句话说,我们要看这款软件给您设计的单词复习次数和复习间隔是否合理。
市场上现有的背单词软件,所采用的算法大致可以分为以下两类:第一类用的是死算法,就是将所有的词汇安排同样的复习次数和复习间隔,举个例子,某些软件会照搬“艾宾浩斯记忆曲线”的原理,分别在1小时后,12小时后,1天后,2天后,5天后,8天后,14天安排单词的复习;这种算法最大的问题就是,明明一个词你已经非常熟悉,但你还是要花和一个生词同样的重复次数来记忆它!这样背诵效率怎么可能提高呢?相比之下,第二类算法则要科学的多,软件通常会采集用户的数据——也就是您对单词的熟悉程度,然后根据这个数据来安排单词的复习次数和复习的间隔。其中的道理是显而易见的,单词越熟悉,你所需的复习次数就越少,也就意味着,在特定的时间段内,复习此单词的间隔也就越长。
那么,软件是如何来采集用户的数据的呢?答案很简单,就是使用一个评分体系。也就是说,您在学习一个单词的时候,系统会要求你根据单词的熟悉程度给这个单词评分。您的评分越贴近实际,软件运算出来的单词复习次数和复习间隔也就越科学。所以说,评分体系的优劣,直接决定了算法是否优秀。
SuperMemo背单词的流程
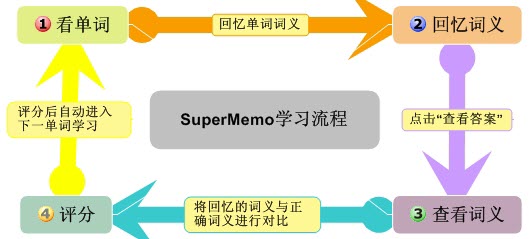
SuperMemo采用“提问+回答”的模式来学习单词。我们来举例说明具体的背诵流程:比如说您要记忆abandon这个词,程序先会显示abandon,此时您要回忆abandon的词义,回忆完后,点击“显示答案”,程序会显示词义,然后您根据单词的熟悉程度来对这个单词进行评分,评分结束后进行下一个词条的学习。
对比SuperMemo与同类软件的评分体系
我们选择国内比较有代表性的某“智能记忆”软件来进行评分体系的对比。先来看SuperMemo的评分体系。
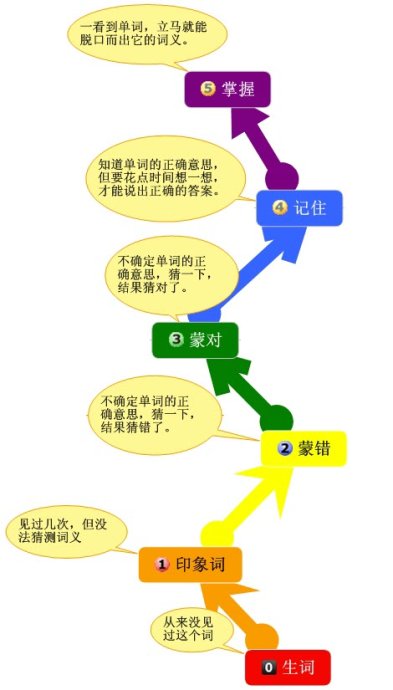
SuperMemo将单词按熟悉程度分成6级,分别表示为0-5,5是最高级别,级别划分如下:
5.掌握:一看到单词,立马就能脱口而出它的词义。这类词基本上不怎么要去记;
4.记住:知道单词的正确意思,但要花点时间想一想,才能说出正确的答案,而且你非常肯定这个答案是正确的。这类词很好突破,按照记忆曲线巩固一定时间, 就可以归到第5类词中去。
3.蒙对:不确定单词的正确意思,猜一下,结果猜对了。脑子里在想,这个单词的词义究竟是A呢?还是B?蒙一下吧,结果你蒙对了。
2.蒙错:不确定单词的正确意思,猜一下,结果猜错了。一看到答案时却发现:“啊,原来是这个意思,我知道的!”2、3两类的单词与其它各类词最根本的区别是,这种词你已经很熟悉(与0、1类词的区别),但无法肯定它的正确词义(与4、5类词的区别),随着猜对次数的不断增加,你对这个词的词义会由起初的“不确定”逐步过渡到“确定”,也就是说,逐步进入4、5类词的范围。
1.印象词:这种词你见过几次,只是模模糊糊中有些印象而已。这类词与2、3两类相比,其区别是“连猜测都无从猜起”,与0类词的区别则是比它多见过几次,稍稍有些印象。
0.生词:完完全全的生词,你见都没见过。这种词在经过几个回合的重复之后,很快就能进入1类词的范围,变成“好象在哪见过”。
再来看看某智能记忆软件的评分体系:
此软件的流程与SuperMemo略有不同:先显示单词=>回忆词义=>根据词义选择“记得”或“忘记”=>程序显示词义=>根据显示的词义判断“正确”或是“不正确”=>进入下一个词条的学习。
从此流程来看,它的评分体系是这样的:
- 记得=>正确:相当于将SuperMemo的4、5两类合并;
- 记得=>不正确:相当于SuperMemo中的第2类,即“蒙错”;
- 忘记=>正确:勉强可以视作SuperMemo中的第3类,即“蒙对”;
- 忘记=>不正确:相当于将SuperMemo的0,1两类合并;
但该软件可能隐藏了一个评分级别,即根据选择“记得”和“忘记”的反应时间来将“记得=>正确”这一类进行拆分。
从比较中我们不难看出,该软件的评分体系相当于SuperMemo的简化版,相比之下,SuperMemo的评分体系条理更加清晰,层次更为丰富。“智能记忆”的主要问题发生在3、4这两个层次的划分上,我们不妨举例来说明:
例1:您从来没有见过这个词,您肯定会选“忘记”,这时有两种可能:1)答案正确;2)答案不正确
再来看例2:您看到一个挺熟的词,就是不大确定它的词义,您也会选“忘记”,同样也会有两种可能:1)答案正确;2)答案不正确
我们假定在这两个例子中您的选择都是1,即“答案正确”,这个时候问题就出来了,事实上,例1里的词应该得到更多的复习次数和更短的复习间隔,而在该“智能记忆”软件中,它们的复习安排将不会有什么区别;更糟糕的是第二种情况,假如例1的选择是1,例2的选择是2,在这种情形中,熟词却要比生词获得更多的复习次数。这样效率怎么会提高呢?
评分体系是整个算法的大前提,这个前提如果错误的话,后面的算法再怎么科学,所得出的结果也是不科学的。
学会分析SupermMemo2006的数据
学会了使用SuperMemo之后,看着一个个窗口里的数据,你晕不晕?有51%以上的可能是会“晕”的吧。舍得就是曾经“晕”过的人,所以在早些日子,舍得是将学习窗口最大化,拒绝看那些数据的。
用着用着,舍得开始对这些数据产生了兴趣,然后慢慢地去观察,同时学习官方的帮助文件,以掌握其中的规律。事实证明,这个工夫没有白花,看懂了那些关键的数据之后,舍得对掌控自己的学习进度更加得心应手。效率自然刷刷地上升。
下面就让舍得来跟大家分享一下这方面的心得吧!
一、统计窗口
我们先从“统计(Statistics)”窗口开始,为了行文方便,以及更有效地推广汉化版,舍得会在以后的文章里用汉化版的界面来讲解,先上图:
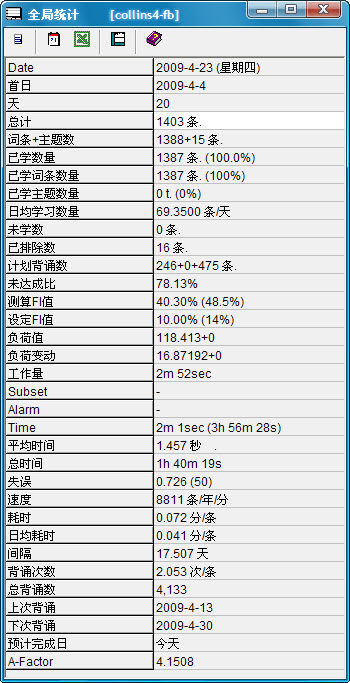
前面的几条字面意义都已经表达得很清楚了,我们从计划背诵数开始讲,这里的原文是“Outstanding”,舍得是根据官方帮助文件中的解释,译成“计划背诵数”,例子中的“246+0+475”,前面一个数字“246”表示你当天要先复习的未掌握的词条数(是你以前累积下来,系统根据你的实际情况安排到当天的量,换句话说,就是你今天第一次打开这个词库时需要先复习的部分),第2个数字“0”和前面的意义一样,只不过它代表的是主题(Topics”第三个数字“475”则表示当天在总复习(也就是“Final Drill”)的过程中你应当复习的总数。在学习的过程中,“246”个词条是要一条一条先复习完毕,再开始学习新材料。每学一条,系统会根据你的评分决定什么时候再次进行复习,一般不会是当天。而在你之后进行学习新材料时,只要你的评分低于“Good”,第三个数字“475”就会加1;学完新材料后,系统会询问你“开始总复习?”,最终显示出来的第三个数字的值就是你当天总复习所需要面对的数字。
未达成比:原文作“Retention”,意为“保持、保留、记忆”,直译很难表达真正的意思——反而会使人越看越糊涂。这个数值基本反映了本词库内你对词的掌握程度,例如,“78.13%”表示我还有78.36%的词汇需要不断巩固——但你必须知道的是,这仅仅是一个估算值。
测算FI值和设定FI值:讲这个之前先来了解一下FI值的概念。FI是Forgetting Index(遗忘指数)的缩写,遗忘指数是你学习过程中失误(指评分在Fail以下,包括Fail)的总次数与重复的总次数的比例,系统用它可以来实现学习速度的调控。测算FI值是在你学习的过程中随你的评分变化而变化的,比如你选择Pass以上级别的时候(包括Pass),这个值会变小,反之则变大。变动的程度也是有区别的,以舍得目前这个词库为例,你选一个Pass,那它只降 0.01%左右,而选Bright则降0.02%左右。设定FI值原文作“Average FI(平均FI值)”,但它这个“平均”,是你在“工具->选项->学习”里进行设定的。系统用这个值来跟测算到的FI值进行比较,测算FI值越大,你所需投入的时间和精力就要相应地增加。官方是这样说的,“如果你感到学得太少,那就把设定FI值调小一点(因为测算FI值不是你直接控制的);如果你感觉按排的重复学习太频繁,那就将设定FI值调高一些。”一般来说,设定FI值在8%-13%之间比较适合。测算FI值后面括号内的数字则是表示当天的一个测算结果,同理,设定FI值则是表示当天的设定结果。
负荷值:测算平均每天的词条或主题的重复次数,这个值等价于所有间隔值(每个词条及主题)的倒数之和——知道或不知道这个对我们的学习帮助并不大。我们只要知道这个能够帮助我们了解到每天的工作量就可以了!
工作量:这是个容易引起误解的词,它是负荷值乘以平均时间的乘积。事实上,实际舍得平均每天所花的可不仅仅是2分52秒。这个值对我们来说意义不是很大。
Subset:子集(这个词可以汉化,但因为它的地址和其它词的地址不一样,有点吃不准,再加上用得较少,索性就不译),讲的是子集里计划学习的词条数量。
Alarm:当你在“计划”里进行设置后,闹钟就开始启动了。不过大多数使用者可以无视这一条。
Time:你花在回答问题上的时间,括号内的是总时间(这个总时间只要你开着SuperMemo它就在跑,所以意义不是很大)
平均时间:你回答问题的平均反应时间,指的是从你按下“下一词条”到“显示答案”之间所花费的这一段时间(取平均值)。这是一个比较重要的参数,同样选Good,花费的时间不同,其结果也是不一样的。
总时间:你在学习过程中总共花去的反应时间(反应时间的概念与上一条相同)。
失误:平均每个词条(包括主题)出错的次数(指的是你选择Fail以下的评分级别,包括Fail),注意未学习的内容不参与计算。括号内的则是当天你所出错的次数。从这个例子看,就是说每一个词条平均出错0.726次,当天则共计出错50次)。非常实用的一个数据。
速度:这是系统预估的你的学习速度,官方称它为“平均知识获取率”。还是把公式说一下吧,速度=(已学词条及主题数/已用天数)/工作量*365,大家把这个例子用公式套一遍就明白了。
耗时、日均耗时:基本上不需要说什么。有兴趣的话可以参看官方帮助文件中的公式。
间隔:每个词条复习所用的平均间隔。间隔在SuperMemo里也是一个很重要的参数。跟我们使用者关系最密切的参数就数它了。记得越牢的词间隔越大,反之则越小。算法说到底,就是计算一个合适间隔的问题。这是SuperMemo的真正价值所在。
背诵次数:其实应该是平均背诵次数,从后面的单位“次/条”可以看出来。
总背诵(次)数:总共重复的次数。舍得在译这个词的时候,总喜欢把它译成“背诵”而不是“重复”。
接下来的两个参数没什么好说的,只是在这里可以学习一下间隔的概念,间隔就是上次背诵和下次背诵之间(逻辑上有点小问题,反正就是两次背诵之间)的天数。
预计完成日:必须解释一下的是,这个“完成”仅仅是指你把未学习的材料变成“已学习”,而不是到达“牢记”的程度。所以当“未学词条/主题数”(pending)为0的时候,预计完成日就永远都显示今天。这个参数的意义在于当你学习的内容比较多的时候,系统会根据你目前的进度来预测你学完所有新材料的那一天。
A-Factor:这个词舍得索性就不译了,系统有时也简写成“AF”,是一个相当重要的参数。它被用来测量词条的难度,AF值越高,难度就越低,反之则越高。目前我们用作例子的这个词库AF值为4.1508,这个难度是相当低了。一般3.5左右的算是难度相对合理的。
好了,上篇的内容我们就介绍到这里,不知道这样的介绍对你的学习有没有帮助呢?如果有什么想法的话,请给舍得留言。欢迎到舍得的学习力博客来探讨SuperMemo的各种问题。
二、元素数据窗口
在学习窗口下方,是一个元素数据窗口,主是作用是实时显示“词条/主题/任务”的数据,这里面有些数据是比较重要的。
照例先上图:
先来看左边一栏:
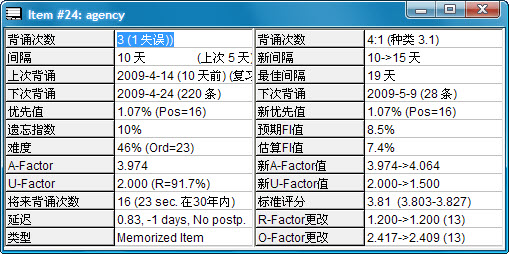
背诵次数:不需要讲了,只是在你学过的词中,如果有“失误”记录的话,会在后面显示出来。
间隔:当前间隔。参看上一节。
上次背诵:告诉你上一次学习是在什么时候。
下次背诵:除了给你日期,括号内的数字表示那一天总共已安排了多少量的学习。如果此处显示的日期是在今天之前的,那说明你有“拖欠”的学习任务。
优先值:非常重要的一个数据!系统用百分比来表示当前词条在优先序列中的位置。例子中前面的“1.07%(Pos=16)”表示它在优先序列中排第16位(总元素数量为1403),舍得推断出来的公式是1403*1.07%+1=16。词条掌握得越差,其优先值(百分比)越高,而其相应的位置也越靠后。
遗忘指数:即FI值,参看上一节中的说明。
难度:重要参数。难度值是根据间隔、失误次数、背诵次数、A-Factor值和首次评分这些数据计算得来的。其百分比值越大,难度越高。难度随成功的次数(选Pass以上的评分)增加而降低,随失败次数(Fail以下的评分)的增加而升高。正常的难度范围是16%-64%,超过64%的话就要好好分析了,是记忆冲突、单词太难?还是其他原因?括号中的Ord值则是所有数据根据难度值排序得来,Ord值越小,词就越“简单”。
A-Factor:参看上一节。
U-Factor:对SuperMemo的算法来说这是个相当重要的参数,但对我们使用才说,实际意义并不是很大,你不知道也没关系。它是用“上次背诵”中的间隔除以间隔值得出的。在本例中,即10/5=2.
将来背诵次数:预估在未来三十年内你需要重复背诵这个词的次数,非常有趣的一个数据。
延迟:描述延迟的情况,这个值是用当前的间隔值除以最佳间隔值得出来的。最佳间隔的数据已经被隐藏——右栏显示的只是下一次的最佳间隔值。
类型:显示当前元素类型是已学还是未学等,Memorized表示已学,Pending则表示未经学习的新材料。
接下来我们再来看右栏,右栏的数据是你在选择评分级别后才显示的,总复习的材料中将不显示这一栏数据:
背诵次数:意思跟前面一样,只是显示的内容和格式有区别,它将当前背诵的次数也加进去了。在本例中,“4:1”表示正确4次,失误1次,总共背诵了5次。后面的“种类”这个词,原文是“Cat(=Category)”,这个种类值是根据你的背诵历史记录来分析得出的,值越高说明这个词对你来说越难。
新间隔:显示了当前的间隔和下次的间隔。下次的间隔值为15,表示当前的日期和下次背诵日期间隔15天,下次背诵日期是5月9日。
最佳间隔:最佳间隔只是一个参考值,可理解为“理论值”。舍得判断这是用来计算“延迟”值而设定的。实际上我们用的间隔值是“新间隔”。
下次背诵和新优先值,这不难理解,不再赘述。
预期FI值(Expected FI)、估算FI值(Estimated FI):注意和上一节中讲的测算FI值(Measured FI)和设定FI值(Average FI)的不同之处在于。上一节中的两个值是整体的一个比例,而这两个值是针对单一的元素。预期FI值反映了回忆的难度,值越大难度越高。而估算FI值则是根据你当前的评分用SuperMemo的算法对预期FI值进行修正得来。大家注意观察一下不同的评分对估算FI值所带来的改变。另外,学习新材料的时候这两个值是没有的。
新的A-Fator值和新的U-Factor值:分别参看A-Factor和U-Factor。
标准评分:系统利用算法得出的一个评分值,与你的评分值密切相关。
R-Factor更改和O-Factor更改:SuperMemo中的“Factor”很多,除了前面讲到的AF、UF,这里又来了RF和OF。这里的“R”是“Retension”的缩写(上一篇舍得讲到过,将它译作“未达成比”),而“O”是optimal的缩写。这两个Factor涉及到复杂的矩阵运算。对我们使用者来说,意义并不是很大。
